
We had an exciting week at NVIDIA GTC, where we shared how we’ve leveraged the open-source NVIDIA PhysicsNeMo (formerly Modulus) DoMINO model architecture to deploy advanced Physics AI capabilities in collaboration with two partners: Rune Aero and nTop. This is the same architecture powering the Real Time Wind Tunnel blueprint we previously demonstrated at SuperComputing 24.
The energy was buzzing in the Design & Simulation section of the exhibition floor. Our booth videos featuring Rune Aero and nTop drew a lot of attention–check them out if you didn’t have a chance to stop by.
After a weekend to recover from all the action, we’re excited to share a technical contribution to the PhysicsNeMo repository – one that benefits anyone training DoMINO models. Read on for a summary, or dive into the pull request for full technical details.
Luminary’s contribution to NVIDIA PhysicsNeMo
Training machine learning models for physics-based simulations is inherently computationally intensive. But surprisingly, the primary bottleneck isn’t always where you’d expect. While working with the DoMINO model architecture, our team discovered that data preparation and loading consumed over 100x more computational resources than the actual training process.
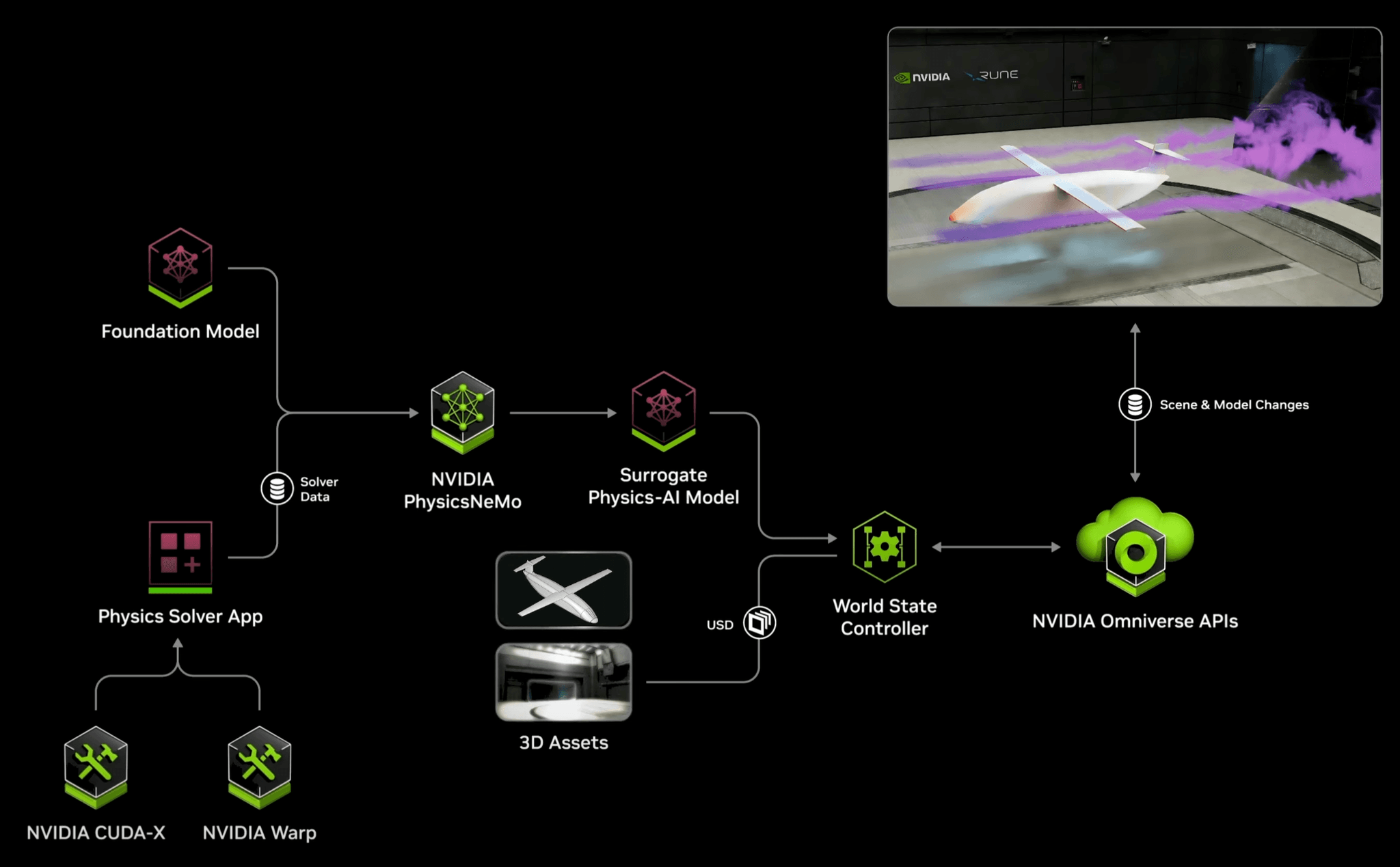
NVIDIA Omniverse™ Blueprint
This inefficiency was especially pronounced when computing spatial relationships between neighboring points in simulation datasets – an operation that remained unchanged throughout training but was being recomputed each training step.
To address this, we implemented a caching mechanism that fundamentally improves the training pipeline. The solution is conceptually simple: since the relationships between neighboring points remain constant throughout training, these calculations should only be performed once. The new implementation preprocesses this data, efficiently stores the essential neighbor indices, and facilitates parallel data loading using multiple workers.
The resulting performance improvements are dramatic: training epochs now execute up to 50 times faster, while data loading has been accelerated by a factor of 8. In one case, a model that previously required nearly five days to train can now be completed in just two hours. For organizations leveraging DoMINO—including Luminary—this opens the door to projects that were previously infeasible. In fact, these improvements enabled us to meet aggressive deadlines while preparing AI models for our NVIDIA GTC demonstrations—with time to spare.
A continued commitment to collaboration
This contribution underscores Luminary’s broader commitment to advancing Physics AI and fostering collaboration with the open-source ecosystem. Looking ahead, we have additional open-source initiatives in progress and look forward to sharing those developments soon!

